9.9. Date/Time Functions and Operators
Table 9-28 shows the available functions for date/time value processing, with details appearing in the following subsections. Table 9-27 illustrates the behaviors of the basic arithmetic operators (+, *, etc.). For formatting functions, refer to Section 9.8. You should be familiar with the background information on date/time data types from Section 8.5.
All the functions and operators described below that take time or timestamp inputs actually come in two variants: one that takes time with time zone or timestamp with time zone, and one that takes time without time zone or timestamp without time zone. For brevity, these variants are not shown separately. Also, the + and * operators come in commutative pairs (for example both date + integer and integer + date); we show only one of each such pair.
Table 9-27. Date/Time Operators
| Operator | Example | Result |
|---|---|---|
| + | date '2001-09-28' + integer '7' | date '2001-10-05' |
| + | date '2001-09-28' + interval '1 hour' | timestamp '2001-09-28 01:00:00' |
| + | date '2001-09-28' + time '03:00' | timestamp '2001-09-28 03:00:00' |
| + | interval '1 day' + interval '1 hour' | interval '1 day 01:00:00' |
| + | timestamp '2001-09-28 01:00' + interval '23 hours' | timestamp '2001-09-29 00:00:00' |
| + | time '01:00' + interval '3 hours' | time '04:00:00' |
| - | - interval '23 hours' | interval '-23:00:00' |
| - | date '2001-10-01' - date '2001-09-28' | integer '3' (days) |
| - | date '2001-10-01' - integer '7' | date '2001-09-24' |
| - | date '2001-09-28' - interval '1 hour' | timestamp '2001-09-27 23:00:00' |
| - | time '05:00' - time '03:00' | interval '02:00:00' |
| - | time '05:00' - interval '2 hours' | time '03:00:00' |
| - | timestamp '2001-09-28 23:00' - interval '23 hours' | timestamp '2001-09-28 00:00:00' |
| - | interval '1 day' - interval '1 hour' | interval '1 day -01:00:00' |
| - | timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00' | interval '1 day 15:00:00' |
| * | 900 * interval '1 second' | interval '00:15:00' |
| * | 21 * interval '1 day' | interval '21 days' |
| * | double precision '3.5' * interval '1 hour' | interval '03:30:00' |
| / | interval '1 hour' / double precision '1.5' | interval '00:40:00' |
Table 9-28. Date/Time Functions
| Function | Return Type | Description | Example | Result |
|---|---|---|---|---|
age(timestamp, timestamp) | interval | Subtract arguments, producing a "symbolic" result that uses years and months | age(timestamp '2001-04-10', timestamp '1957-06-13') | 43 years 9 mons 27 days |
age(timestamp) | interval | Subtract from current_date (at midnight) | age(timestamp '1957-06-13') | 43 years 8 mons 3 days |
clock_timestamp() | timestamp with time zone | Current date and time (changes during statement execution); see Section 9.9.4 | ||
current_date | date | Current date; see Section 9.9.4 | ||
current_time | time with time zone | Current time of day; see Section 9.9.4 | ||
current_timestamp | timestamp with time zone | Current date and time (start of current transaction); see Section 9.9.4 | ||
date_part(text, timestamp) | double precision | Get subfield (equivalent to extract); see Section 9.9.1 | date_part('hour', timestamp '2001-02-16 20:38:40') | 20 |
date_part(text, interval) | double precision | Get subfield (equivalent to extract); see Section 9.9.1 | date_part('month', interval '2 years 3 months') | 3 |
date_trunc(text,timestamp) | timestamp | Truncate to specified precision; see also Section 9.9.2 | date_trunc('hour', timestamp '2001-02-16 20:38:40') | 2001-02-16 20:00:00 |
extract(field fromtimestamp) | double precision | Get subfield; see Section 9.9.1 | extract(hour from timestamp '2001-02-16 20:38:40') | 20 |
extract(field frominterval) | double precision | Get subfield; see Section 9.9.1 | extract(month from interval '2 years 3 months') | 3 |
isfinite(date) | boolean | Test for finite date (not +/-infinity) | isfinite(date '2001-02-16') | true |
isfinite(timestamp) | boolean | Test for finite time stamp (not +/-infinity) | isfinite(timestamp '2001-02-16 21:28:30') | true |
isfinite(interval) | boolean | Test for finite interval | isfinite(interval '4 hours') | true |
justify_days(interval) | interval | Adjust interval so 30-day time periods are represented as months | justify_days(interval '35 days') | 1 mon 5 days |
justify_hours(interval) | interval | Adjust interval so 24-hour time periods are represented as days | justify_hours(interval '27 hours') | 1 day 03:00:00 |
justify_interval(interval) | interval | Adjust interval using justify_days and justify_hours, with additional sign adjustments | justify_interval(interval '1 mon -1 hour') | 29 days 23:00:00 |
localtime | time | Current time of day; see Section 9.9.4 | ||
localtimestamp | timestamp | Current date and time (start of current transaction); see Section 9.9.4 | ||
now() | timestamp with time zone | Current date and time (start of current transaction); see Section 9.9.4 | ||
statement_timestamp() | timestamp with time zone | Current date and time (start of current statement); see Section 9.9.4 | ||
timeofday() | text | Current date and time (like clock_timestamp, but as a text string); see Section 9.9.4 | ||
transaction_timestamp() | timestamp with time zone | Current date and time (start of current transaction); see Section 9.9.4 |
In addition to these functions, the SQL OVERLAPS operator is supported:
(start1, end1) OVERLAPS (start2, end2) (start1, length1) OVERLAPS (start2, length2)
This expression yields true when two time periods (defined by their endpoints) overlap, false when they do not overlap. The endpoints can be specified as pairs of dates, times, or time stamps; or as a date, time, or time stamp followed by an interval. When a pair of values is provided, either the start or the end can be written first; OVERLAPS automatically takes the earlier value of the pair as the start. Each time period is considered to represent the half-open interval start <= time < end, unless start and end are equal in which case it represents that single time instant. This means for instance that two time periods with only an endpoint in common do not overlap.
SELECT (DATE '2001-02-16', DATE '2001-12-21') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: true
SELECT (DATE '2001-02-16', INTERVAL '100 days') OVERLAPS
(DATE '2001-10-30', DATE '2002-10-30');
Result: false
SELECT (DATE '2001-10-29', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: false
SELECT (DATE '2001-10-30', DATE '2001-10-30') OVERLAPS
(DATE '2001-10-30', DATE '2001-10-31');
Result: true
When adding an interval value to (or subtracting an interval value from) a timestamp with time zone value, the days component advances (or decrements) the date of the timestamp with time zoneby the indicated number of days. Across daylight saving time changes (with the session time zone set to a time zone that recognizes DST), this means interval '1 day' does not necessarily equal interval '24 hours'. For example, with the session time zone set to CST7CDT, timestamp with time zone '2005-04-02 12:00-07' + interval '1 day' will produce timestamp with time zone '2005-04-03 12:00-06', while adding interval '24 hours' to the same initial timestamp with time zone produces timestamp with time zone '2005-04-03 13:00-06', as there is a change in daylight saving time at 2005-04-03 02:00 in time zone CST7CDT.
Note there can be ambiguity in the months returned by age because different months have a different number of days. PostgreSQL's approach uses the month from the earlier of the two dates when calculating partial months. For example, age('2004-06-01', '2004-04-30') uses April to yield 1 mon 1 day, while using May would yield 1 mon 2 days because May has 31 days, while April has only 30.
9.9.1. EXTRACT, date_part
EXTRACT(field FROM source)
The extract function retrieves subfields such as year or hour from date/time values. source must be a value expression of type timestamp, time, or interval. (Expressions of type date are cast totimestamp and can therefore be used as well.) field is an identifier or string that selects what field to extract from the source value. The extract function returns values of type double precision. The following are valid field names:
- century
The century
SELECT EXTRACT(CENTURY FROM TIMESTAMP '2000-12-16 12:21:13'); Result: 20 SELECT EXTRACT(CENTURY FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 21
The first century starts at 0001-01-01 00:00:00 AD, although they did not know it at the time. This definition applies to all Gregorian calendar countries. There is no century number 0, you go from -1 century to 1 century. If you disagree with this, please write your complaint to: Pope, Cathedral Saint-Peter of Roma, Vatican.
PostgreSQL releases before 8.0 did not follow the conventional numbering of centuries, but just returned the year field divided by 100.
- day
For timestamp values, the day (of the month) field (1 - 31) ; for interval values, the number of days
SELECT EXTRACT(DAY FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 16 SELECT EXTRACT(DAY FROM INTERVAL '40 days 1 minute'); Result: 40
- decade
The year field divided by 10
SELECT EXTRACT(DECADE FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 200
- dow
The day of the week as Sunday (0) to Saturday (6)
SELECT EXTRACT(DOW FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 5
Note that
extract's day of the week numbering differs from that of theto_char(..., 'D')function.- doy
The day of the year (1 - 365/366)
SELECT EXTRACT(DOY FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 47
- epoch
For date and timestamp values, the number of seconds since 1970-01-01 00:00:00 UTC (can be negative); for interval values, the total number of seconds in the interval
SELECT EXTRACT(EPOCH FROM TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40.12-08'); Result: 982384720.12 SELECT EXTRACT(EPOCH FROM INTERVAL '5 days 3 hours'); Result: 442800
Here is how you can convert an epoch value back to a time stamp:
SELECT TIMESTAMP WITH TIME ZONE 'epoch' + 982384720.12 * INTERVAL '1 second';
(The
to_timestampfunction encapsulates the above conversion.)- hour
The hour field (0 - 23)
SELECT EXTRACT(HOUR FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 20
- isodow
The day of the week as Monday (1) to Sunday (7)
SELECT EXTRACT(ISODOW FROM TIMESTAMP '2001-02-18 20:38:40'); Result: 7
This is identical to dow except for Sunday. This matches the ISO 8601 day of the week numbering.
- isoyear
The ISO 8601 week-numbering year that the date falls in (not applicable to intervals)
SELECT EXTRACT(ISOYEAR FROM DATE '2006-01-01'); Result: 2005 SELECT EXTRACT(ISOYEAR FROM DATE '2006-01-02'); Result: 2006
Each ISO 8601 week-numbering year begins with the Monday of the week containing the 4th of January, so in early January or late December the ISO year may be different from the Gregorian year. See the week field for more information.
This field is not available in PostgreSQL releases prior to 8.3.
- microseconds
The seconds field, including fractional parts, multiplied by 1 000 000; note that this includes full seconds
SELECT EXTRACT(MICROSECONDS FROM TIME '17:12:28.5'); Result: 28500000
- millennium
The millennium
SELECT EXTRACT(MILLENNIUM FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 3
Years in the 1900s are in the second millennium. The third millennium started January 1, 2001.
PostgreSQL releases before 8.0 did not follow the conventional numbering of millennia, but just returned the year field divided by 1000.
- milliseconds
The seconds field, including fractional parts, multiplied by 1000. Note that this includes full seconds.
SELECT EXTRACT(MILLISECONDS FROM TIME '17:12:28.5'); Result: 28500
- minute
The minutes field (0 - 59)
SELECT EXTRACT(MINUTE FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 38
- month
For timestamp values, the number of the month within the year (1 - 12) ; for interval values, the number of months, modulo 12 (0 - 11)
SELECT EXTRACT(MONTH FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 2 SELECT EXTRACT(MONTH FROM INTERVAL '2 years 3 months'); Result: 3 SELECT EXTRACT(MONTH FROM INTERVAL '2 years 13 months'); Result: 1
- quarter
The quarter of the year (1 - 4) that the date is in
SELECT EXTRACT(QUARTER FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 1
- second
The seconds field, including fractional parts (0 - 59[1])
SELECT EXTRACT(SECOND FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 40 SELECT EXTRACT(SECOND FROM TIME '17:12:28.5'); Result: 28.5
- timezone
The time zone offset from UTC, measured in seconds. Positive values correspond to time zones east of UTC, negative values to zones west of UTC. (Technically, PostgreSQL uses UT1 because leap seconds are not handled.)
- timezone_hour
The hour component of the time zone offset
- timezone_minute
The minute component of the time zone offset
- week
The number of the ISO 8601 week-numbering week of the year. By definition, ISO weeks start on Mondays and the first week of a year contains January 4 of that year. In other words, the first Thursday of a year is in week 1 of that year.
In the ISO week-numbering system, it is possible for early-January dates to be part of the 52nd or 53rd week of the previous year, and for late-December dates to be part of the first week of the next year. For example, 2005-01-01 is part of the 53rd week of year 2004, and 2006-01-01 is part of the 52nd week of year 2005, while 2012-12-31 is part of the first week of 2013. It's recommended to use the isoyear field together with week to get consistent results.
SELECT EXTRACT(WEEK FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 7
- year
The year field. Keep in mind there is no 0 AD, so subtracting BC years from AD years should be done with care.
SELECT EXTRACT(YEAR FROM TIMESTAMP '2001-02-16 20:38:40'); Result: 2001
The extract function is primarily intended for computational processing. For formatting date/time values for display, see Section 9.8.
The date_part function is modeled on the traditional Ingres equivalent to the SQL-standard function extract:
date_part('field', source)
Note that here the field parameter needs to be a string value, not a name. The valid field names for date_part are the same as for extract.
SELECT date_part('day', TIMESTAMP '2001-02-16 20:38:40');
Result: 16
SELECT date_part('hour', INTERVAL '4 hours 3 minutes');
Result: 4
9.9.2. date_trunc
The function date_trunc is conceptually similar to the trunc function for numbers.
date_trunc('field', source)
source is a value expression of type timestamp or interval. (Values of type date and time are cast automatically to timestamp or interval, respectively.) field selects to which precision to truncate the input value. The return value is of type timestamp or interval with all fields that are less significant than the selected one set to zero (or one, for day and month).
Valid values for field are:
| microseconds |
| milliseconds |
| second |
| minute |
| hour |
| day |
| week |
| month |
| quarter |
| year |
| decade |
| century |
| millennium |
Examples:
SELECT date_trunc('hour', TIMESTAMP '2001-02-16 20:38:40');
Result: 2001-02-16 20:00:00
SELECT date_trunc('year', TIMESTAMP '2001-02-16 20:38:40');
Result: 2001-01-01 00:00:00
9.9.3. AT TIME ZONE
The AT TIME ZONE construct allows conversions of time stamps to different time zones. Table 9-29 shows its variants.
Table 9-29. AT TIME ZONE Variants
| Expression | Return Type | Description |
|---|---|---|
| timestamp without time zone AT TIME ZONE zone | timestamp with time zone | Treat given time stamp without time zone as located in the specified time zone |
| timestamp with time zone AT TIME ZONE zone | timestamp without time zone | Convert given time stamp with time zone to the new time zone, with no time zone designation |
| time with time zone AT TIME ZONE zone | time with time zone | Convert given time with time zone to the new time zone |
In these expressions, the desired time zone zone can be specified either as a text string (e.g., 'PST') or as an interval (e.g., INTERVAL '-08:00'). In the text case, a time zone name can be specified in any of the ways described in Section 8.5.3.
Examples (assuming the local time zone is PST8PDT):
SELECT TIMESTAMP '2001-02-16 20:38:40' AT TIME ZONE 'MST'; Result: 2001-02-16 19:38:40-08 SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40-05' AT TIME ZONE 'MST'; Result: 2001-02-16 18:38:40
The first example takes a time stamp without time zone and interprets it as MST time (UTC-7), which is then converted to PST (UTC-8) for display. The second example takes a time stamp specified in EST (UTC-5) and converts it to local time in MST (UTC-7).
The function timezone(zone, timestamp) is equivalent to the SQL-conforming construct timestamp AT TIME ZONE zone.
9.9.4. Current Date/Time
PostgreSQL provides a number of functions that return values related to the current date and time. These SQL-standard functions all return values based on the start time of the current transaction:
CURRENT_DATE CURRENT_TIME CURRENT_TIMESTAMP CURRENT_TIME(precision) CURRENT_TIMESTAMP(precision) LOCALTIME LOCALTIMESTAMP LOCALTIME(precision) LOCALTIMESTAMP(precision)
CURRENT_TIME and CURRENT_TIMESTAMP deliver values with time zone; LOCALTIME and LOCALTIMESTAMP deliver values without time zone.
CURRENT_TIME, CURRENT_TIMESTAMP, LOCALTIME, and LOCALTIMESTAMP can optionally take a precision parameter, which causes the result to be rounded to that many fractional digits in the seconds field. Without a precision parameter, the result is given to the full available precision.
Some examples:
SELECT CURRENT_TIME; Result: 14:39:53.662522-05 SELECT CURRENT_DATE; Result: 2001-12-23 SELECT CURRENT_TIMESTAMP; Result: 2001-12-23 14:39:53.662522-05 SELECT CURRENT_TIMESTAMP(2); Result: 2001-12-23 14:39:53.66-05 SELECT LOCALTIMESTAMP; Result: 2001-12-23 14:39:53.662522
Since these functions return the start time of the current transaction, their values do not change during the transaction. This is considered a feature: the intent is to allow a single transaction to have a consistent notion of the "current" time, so that multiple modifications within the same transaction bear the same time stamp.
Note: Other database systems might advance these values more frequently.
PostgreSQL also provides functions that return the start time of the current statement, as well as the actual current time at the instant the function is called. The complete list of non-SQL-standard time functions is:
transaction_timestamp() statement_timestamp() clock_timestamp() timeofday() now()
transaction_timestamp() is equivalent to CURRENT_TIMESTAMP, but is named to clearly reflect what it returns. statement_timestamp() returns the start time of the current statement (more specifically, the time of receipt of the latest command message from the client). statement_timestamp() and transaction_timestamp() return the same value during the first command of a transaction, but might differ during subsequent commands. clock_timestamp() returns the actual current time, and therefore its value changes even within a single SQL command. timeofday() is a historical PostgreSQL function. Like clock_timestamp(), it returns the actual current time, but as a formatted text string rather than a timestamp with time zone value. now() is a traditional PostgreSQL equivalent to transaction_timestamp().
All the date/time data types also accept the special literal value now to specify the current date and time (again, interpreted as the transaction start time). Thus, the following three all return the same result:
SELECT CURRENT_TIMESTAMP; SELECT now(); SELECT TIMESTAMP 'now'; -- incorrect for use with DEFAULT
Tip: You do not want to use the third form when specifying a DEFAULT clause while creating a table. The system will convert now to a timestamp as soon as the constant is parsed, so that when the default value is needed, the time of the table creation would be used! The first two forms will not be evaluated until the default value is used, because they are function calls. Thus they will give the desired behavior of defaulting to the time of row insertion.
9.9.5. Delaying Execution
The following function is available to delay execution of the server process:
pg_sleep(seconds)
pg_sleep makes the current session's process sleep until seconds seconds have elapsed. seconds is a value of type double precision, so fractional-second delays can be specified. For example:
SELECT pg_sleep(1.5);
출처 : https://www.postgresql.org/docs/9.1/functions-datetime.html
'Postgresql' 카테고리의 다른 글
| CONNECT BY LEVEL oracle -> postgresql (0) | 2019.01.11 |
|---|---|
| Postgresql 프로시저 만들기 (0) | 2019.01.08 |
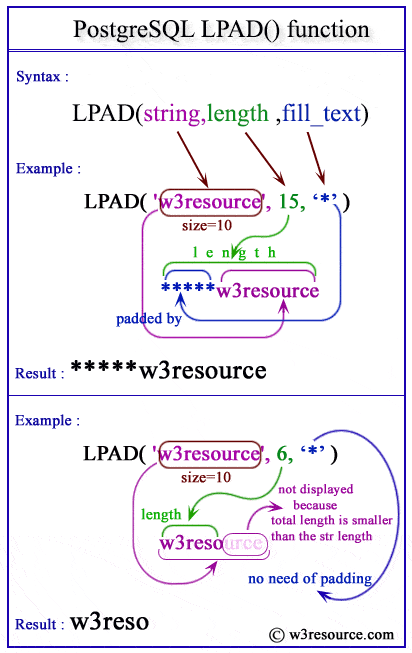
| Postgresql LPAD() function (0) | 2019.01.08 |
| ORACLE Postgresql 변환 (0) | 2018.12.27 |
| Postgresql 스키마 권한 (0) | 2018.12.27 |